How to bypass the Server Bot Check
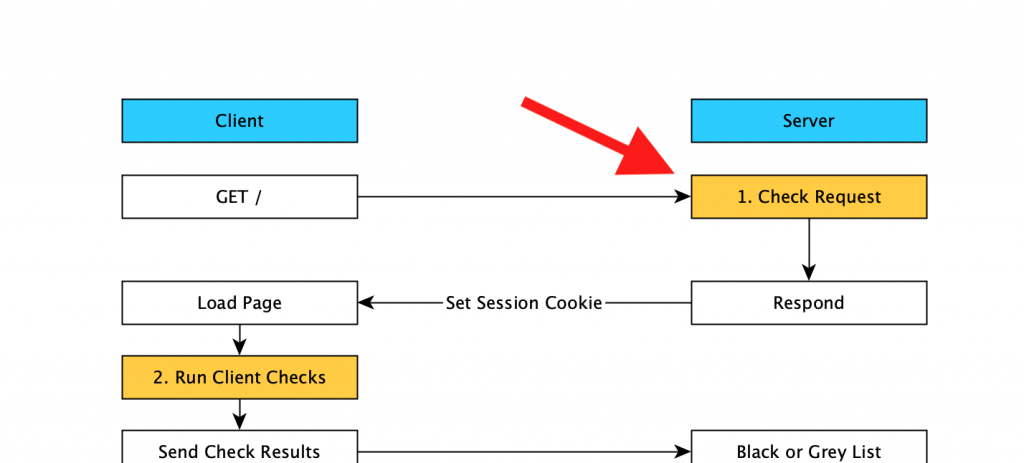
The first check request is where the server checks if your worth sending the base html page to. This doesn’t contain any useful data like prices, this is just “should I even bother responding”. Since we’re a new client at this point (no session history), there’s a limited number of things that can be used to identify us.
- IP Address
- User Agent
- TLS fingerprint
- Time of day
How to bypass the IP Address check
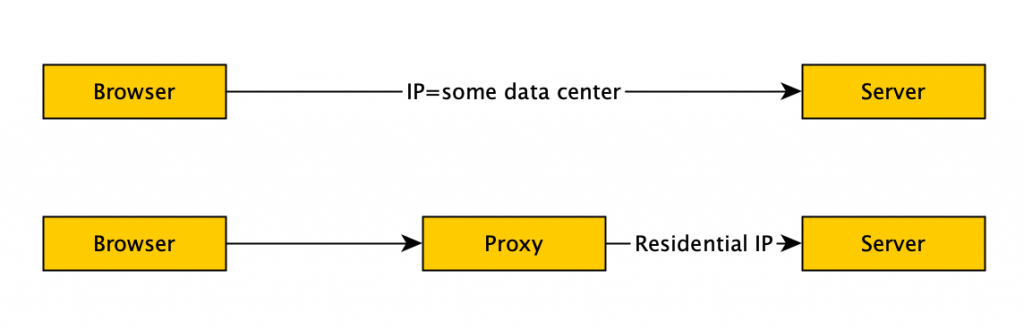
This is actually pretty straight forward. Pay for a good proxy service. There’s a few things to consider:
- You want IP addresses for residential looking locations (not a data center). Since IP ranges for AWS, Digital Ocean etc are publicly available, it’s pretty easy for the defense team to simply do a lookup. Obviously server shouldn’t be checking the price of 2×4’s.
- You want low latency on the connection. Since we’ve just introduced extra hops in our network configuration (and often relatively low speed hops), we can get detected just for having a super slow request profile (see #4 of the castle).
- You don’t want tainted IP addresses. The proxy service should manage most of this, but sometimes specific IPs have been blacklisted by other scrapers and will identify you. I ended up creating an internal IP blacklist based on crawl success rate for specific IPs.
- You don’t want IP hopping during your crawl session. Some services will move your connection between available address for load balancing/host availability. Moving your IP mid-session is a clear indication that you are an attacker and not just someone on their couch surfing the net.
How to bypass the User Agent Check
Every HTTP request includes a User Agent header like the one below.
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 As you can see, that UA tells the server quite a bit. Your platform (Mac/Windows), your browser name and version.
This is actually one of the easiest thing to change. Automated browsers (e.g. selenium/phantomJS/chromewebdriver) usually have a configuration option to override this – that’s what I did.
How to bypass the TLS Check
Secure HTTP/1 sites use TLS over TCP. There’s a few versions of TLS out in the wild right now. Most are on TLS 1.3, but there are still some TLS 1.2 kicking around. This really applies to TLS 1.2 and will be obsolete as a fingerprinting method over the next few years.
Ok, so what’s going on with TLS 1.2 that lets us get fingerprinted?
During the setup phase, the client (us), sends the server something called a “client hello”. We tell the server what we support
- TLS versions
- Cipher suites (encryption methods)
- Compression methods
- Extensions
In TLS 1.2 there 37 possible cipher suites and ~59 extensions supported.
Each TLS client library implements a different set of cipher suites and extensions. Some even implement new/proprietary extensions (e.g. for a while GREASE was only supported by Chrome).
Ok, so what can we do about this?
Implementing TLS Masquerading
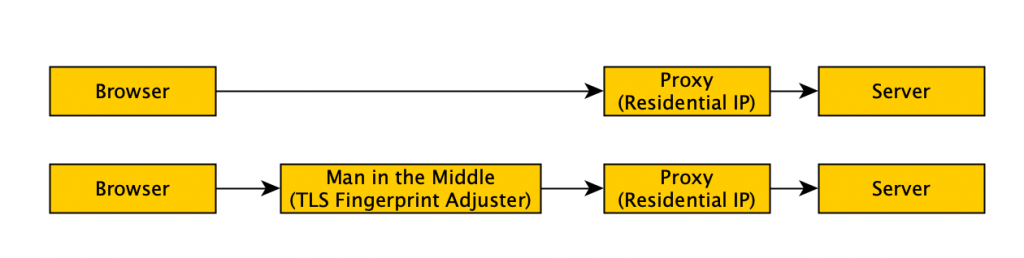
I was using Chrome Webdriver which obviously has a Chrome TLS fingerprint. How can I modify the TLS fingerprint of my browser?
- I could dig into the Chromium source code – that sounds like a TONNE of work
- I could impliment some masquerading code elsewhere (say in Golang where I’m comfortable) and play man-in-the-middle on my browser.
Yes, you heard that right, man-in-the-middle, the attack people typically do to skim bank passwords, or other stuff that is normally encrypted. That’s the one. Except, I was doing this on purpose and had to do some fnaggling to make this work.
Problem 1: How to play man-in-the-middle on yourself
Chrome (and other browsers) actively protect you from man in the middle attacks because they usually have bad consequences. Think bank credential skimming etc. But, we can configure Chrome to accept this new actor.
We can use chrome’s proxy setting to point chrome to our man in the middle (–proxy-server flag). This will send the traffic to our man in the middle. We’ll use an HTTP proxy for this (for reasons I forget atm)
Problem 2: How to adjust the TLS fingerprint
Ok, great our proxy is installed. Now we can tackle the TLS fingerprint problem.
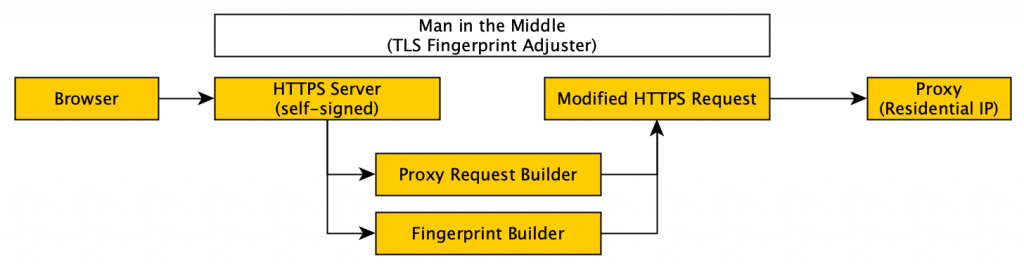
- We need to be a mock HTTPS server to our chrome instance (because the page will contain links to HTTPS and we don’t want to rewrite the page content).
It’s pretty easy to build a mock HTTPS server in our man in the middle (golang) application. We spin up the standard library’s https library and use a self-signed certificate. Chrome of course doesn’t like that, so we need to get it to ignore those errors with –ignore-certificate-errors=true - We need to re-build the chrome requests into something the residential proxy will understand
For this, we can scan in the original request from Chrome, make some tweaks to add our residential proxy authentication headers and forward that on. - We need to add our customized TLS fingerprint
This was a real kettle of fish (that was for you @jlogic). I made a clone of the golang standard library’s TLS package and began implementing all the common parameter types. You can see some of the final product at https://github.com/ntbosscher/utls. It was a lot of slogging, but in the end, I got it working and integrated into the golang http library via some clever interfaces.
How to Bypass the Time of Day Check
Well this is probably the easiest of all the problems.
We need to scan the site during times when regalar people are scanning the sites (or we think they are). During the setup phase of the residential proxy, we can grab the geo location of the IP. Then, we can plug this into a time zone lookup and figure out what the local time is. If it’s 3am, abort. If it’s 9am, 8pm – go, go, go!
So that concludes our Check Request gate. What’s next?
Intro: How I bypassed military-grade bot detection software on popular ecommerce sites
Part 1: How to bypass the Server Bot Check